In the ever-evolving world of technology, machine learning (ML) has rapidly become a cornerstone of innovation, transforming industries and redefining what's possible. Whether you're a budding data scientist eager to make your mark or a seasoned professional looking to stay ahead, understanding the
basic terminology of machine learning is crucial.
The right knowledge of
machine learning terms doesn't just make you sound smart in meetings—it’s also essential for building a successful career in this dynamic field.
In this blog, let’s understand the latest must-know machine learning terminologies and why being updated about them is essential.
Grasping the
key terminology in machine learning is more than just a rite of passage for those new to the field - rather, it's a vital step towards career growth and success. For beginners, these terms are the building blocks that will allow you to dive deeper into complex concepts with confidence. For experienced data scientists, staying updated with these latest terminologies is crucial to keep your skills sharp and knowledge relevant.
With that in mind, let's dive into some of the most important machine-learning terms you need to know.
Artificial Neural Networks (ANNs) can imitate the human brain's structure. They consist of layers of interconnected nodes. ANNs learn from data, making them powerful for tasks like image and speech recognition.
Why It Matters: ANNs are the foundation of complex architectures like deep learning networks. Understanding ANNs gives insights into the capabilities and limitations of ML systems.
Deep Learning is a subset of machine learning. It involves neural networks with many layers. Each layer captures progressively more abstract features from the data. This enables complex tasks like facial recognition and language translation.
Why it Matters: Deep learning is critical in autonomous vehicles, advanced robotics, and AI-driven content creation. Understanding and implementing deep learning models is essential in the AI space.
Overfitting refers to a situation where a model finds unnecessary noise in some training data. This leads to a poor generalisation of new data. Underfitting occurs when the provided model seems to be very easy. It fails to capture the underlying pattern, resulting in weak performance.
Why It Matters: Balancing model complexity is key to building effective ML systems. Identifying and addressing overfitting and underfitting is crucial for real-world performance.
Gradient Descent is an optimisation algorithm. It minimises errors in machine learning models. The algorithm iteratively adjusts model parameters, reducing error. It works like a hiker descending a hill by choosing the steepest path.
Analogy: Gradient descent is like finding the quickest way down a hill. Each step brings you closer to the bottom, where the error is minimised. This concept is foundational for training many ML models, including deep learning ones.
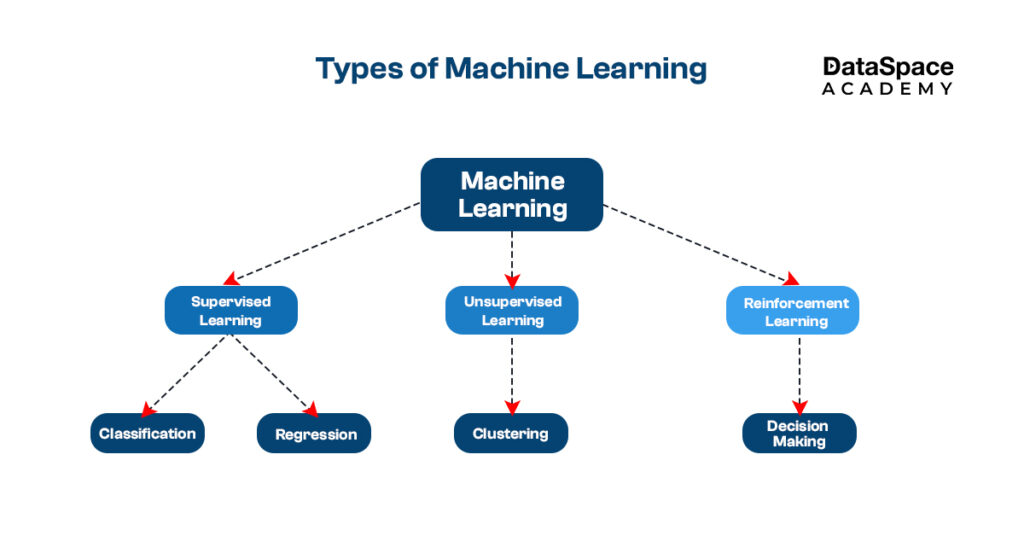
Supervised learning involves training models on labelled data. This means the input comes with the correct output. Unsupervised learning involves analysing data without predefined labels. The model must find patterns or groupings on its own.
Examples:
Why It Matters: These two approaches form the backbone of machine learning. Each is suitable for different tasks. Knowing when to apply supervised versus unsupervised learning impacts the success of ML projects.
A subset of ML, NLP focuses on interactions between computers and human language. NLP techniques enable machines to understand, interpret, and generate human language meaningfully.
Emerging Trends: NLP is crucial in chatbots, voice-activated assistants, and sentiment analysis tools. In 2024, expect NLP to be deeply integrated into customer service, content creation, and mental health applications.
Reinforcement Learning (RL) is a variety of advanced machine learning. An agent learns to make decisions by taking actions in an environment. The agent receives penalties or rewards relative to its actions. Over time, the agent maximises cumulative rewards, developing intelligent behaviour.
Real-World Use Cases: RL drives game-playing AI systems like AlphaGo and chess bots. It's also used in robotics, where agents learn tasks through trial and error.
Hyperparameters are settings that govern the learning process of an ML model. Instances include learning rates and the addition of hidden layers through a neural network. Hyperparameter tuning involves adjusting these settings to improve model performance.
Why It Matters: The right hyperparameters can significantly impact model performance. Tuning these parameters requires a deep understanding of both the model and the data.
Model Evaluation Metrics determine how well an ML model performs. Typical metrics include accuracy, precision, recall, and the F1-score. Each offers different insights into model performance.
Application: Accuracy is often the go-to metric. However, it's not always the best choice, especially with imbalanced datasets. In such cases, metrics like precision or recall may be more informative.
Transfer Learning is an ML technique. It involves reusing a model developed for one task as the starting point for a model on a second task. This approach is especially useful when data for the second task is limited.
Why It Matters: Transfer learning allows quicker and more effective model development. It's gaining traction, particularly in fields like computer vision and NLP. Large, pre-trained models can be fine-tuned for specific tasks.
Mastering machine learning terminology is essential for aspiring and existing professionals in the field. Whether you're dealing with artificial neural networks or fine-tuning hyperparameters, each term represents a key concept. Understanding these terms propels your knowledge and career forward. It helps you navigate the complexities of ML and makes you a more effective ML expert. Consider enrolling in our advanced
machine learning course to deepen your expertise. The right knowledge is the foundation of success in this exciting, ever-evolving field.

 2. Communication and Collaboration: ML engineers often have to work in collaboration with other team members. They might also be required to explain ML projects to stakeholders. Whether you're discussing the nuances of a deep learning model or explaining why a certain algorithm was chosen- being fluent in ML terminology allows for more efficient and productive conversations.
2. Communication and Collaboration: ML engineers often have to work in collaboration with other team members. They might also be required to explain ML projects to stakeholders. Whether you're discussing the nuances of a deep learning model or explaining why a certain algorithm was chosen- being fluent in ML terminology allows for more efficient and productive conversations.











