AI needs data to learn and predict results. But often collecting and compiling data can be pricey and time-consuming. Also, real data could be biased, imbalanced, and unusable due to privacy regulations. To bypass these limitations, AI proponents and deep neural network developers are now banking on
Synthetic Data.
The blog below lists all the prime
benefits of synthetic data.
Synthetic data is an artificially generated class of data that works as an effective alternative to real data. Contrary to the real data collected from the real world, synthetic data is “made-up” information generated by computer simulations or algorithms. Although synthetic data can be artificial, it reflects real-world data both statistically and mathematically.
| Real Data | Synthetic Data |
| Derived | Generated |
| Collected from real-world sources and natural settings | Produced through various computer algorithms and models |
| Original data | Emulates statistical properties of original data |
| Might carry sensitive information | Mimics real data yet without sensitive information |
| Availability based on existence of relevant datasets | Generated as per demand |
When comparing
synthetic data vs real data, multiple researchers have confirmed that synthetic data is as reliable - or in some cases- even better for training an AI model. Join our
machine learning certification course to learn more about synthetic data.
Most organisations are leveraging synthetic data to enhance small, existing datasets. Plus, synthetic data can make it easier to test AI models when real data is inaccessible, classified, or shifted. Also, synthetic data is highly useful in testing a new system when either no live data exists or when data is biased. In fact, by 2030 synthetic data will completely overshadow real data in AI models (Source: Gartner).
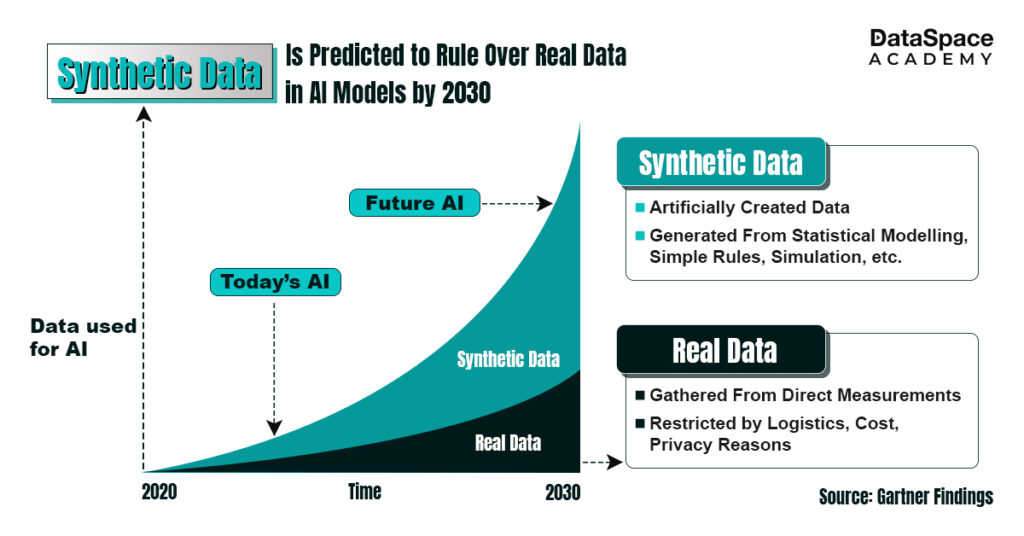
Undoubtedly, synthetic data hold immense possibilities and benefits. Let’s dive into the
synthetic data benefits in the section below.
Among the top
benefits of Synthetic Data, data privacy and data security claim the top berth. Plus, artificially accumulated data is safe and completely anonymous. Below we have listed the key reasons behind the rising popularity of synthetic data in the current times.

However, synthetic data is not free from limitations. Critics raise the question of accuracy of synthetic data in representing real-world scenarios. Oftentimes researchers resort to advanced techniques like generative adversarial networks (GANs) and domain adaptation to make up for the authenticity of the data . These methods aim to create synthetic data that closely mimics the statistical properties and patterns of real data.
Another
limitation of synthetic data is ethical implications. Researchers have pointed out that when synthetic data is used to replace or manipulate real data, it largely happens without proper disclosure. This could lead to skewed results or misleading conclusions.
Despite the challenges, synthetic data is fast gaining traction given its long list of benefits of real data.
Synthetic data resolves many glitches, including data privacy and security. Since artificial data mimics real-world patterns while ensuring individual anonymity, it helps to ensure the privacy of the subject. Plus,
synthetic dataset generation is cheaper and easy to procure.
Speaking about the future, experts have predicted the rise of
generative ai synthetic data in the coming times. The Gen AI integration will help to produce richer or fairer versions of real-world data, thereby improving the quality of synthetic data. Businesses will increasingly rely on synthetic data to reduce costs, enhance privacy, and overcome data limitations, resulting in improved decision-making and innovation. Sectors like healthcare, finance, and manufacturing will benefit from more accurate simulations and models, driving innovation and efficiency.












